SQL基礎:解析SQL?Server?CDC配合Kafka?Connect監聽數據變化的問題
時間:2024-02-08 11:17作者:下載吧人氣:33
寫在前面
好久沒更新Blog了,從CRUD Boy轉型大數據開發,拉寬了不少的知識面,從今年年初開始籌備、組建、招兵買馬,到現在穩定開搞中,期間踏過無數的火坑,也許除了這篇還很寫上三四篇。
進入主題,通常企業為了實現數據統計、數據分析、數據挖掘、解決信息孤島等全局數據的系統化運作管理 ,為BI、經營分析、決策支持系統等深度開發應用奠定基礎,挖掘數據價值 ,企業會開始著手建立數據倉庫,數據中臺。而這些數據來源則來自于企業的各個業務系統的數據或爬取外部的數據,從業務系統數據到數據倉庫的過程就是一個ETL(Extract-Transform-Load)行為,包括了采集、清洗、數據轉換等主要過程,通常異構數據抽取轉換使用Sqoop、DataX等,日志采集Flume、Logstash、Filebeat等。
數據抽取分為全量抽取和增量抽取,全量抽取類似于數據遷移或數據復制,全量抽取很好理解;增量抽取在全量的基礎上做增量,只監聽、捕捉動態變化的數據。如何捕捉數據的變化是增量抽取的關鍵,一是準確性,必須保證準確的捕捉到數據的動態變化,二是性能,不能對業務系統造成太大的壓力。
增量抽取方式
通常增量抽取有幾種方式,各有優缺點。
1. 觸發器
在源數據庫上的目標表創建觸發器,監聽增、刪、改操作,捕捉到數據的變更寫入臨時表。
優點:操作簡單、規則清晰,對源表不影響;
缺點:對源數據庫有侵入,對業務系統有一定的影響;
2. 全表比對
在ETL過程中,抽取方建立臨時表待全量抽取存儲,然后在進行比對數據。
優點:對源數據庫、源表都無需改動,完全交付ETL過程處理,統一管理;
缺點:ETL效率低、設計復雜,數據量越大,速度越慢,時效性不確定;
3. 全表刪除后再插入
在抽取數據之前,先將表中數據清空,然后全量抽取。
優點:ETL 操作簡單,速度快。
缺點:全量抽取一般采取T+1的形式,抽取數據量大的表容易對數據庫造成壓力;
4. 時間戳
時間戳的方式即在源表上增加時間戳列,對發生變更的表進行更新,然后根據時間戳進行提取。
優點:操作簡單,ELT邏輯清晰,性能比較好;
缺點:對業務系統有侵入,數據庫表也需要額外增加字段。對于老的業務系統可能不容易做變更。
5. CDC方式
變更數據捕獲Change Data Capture(簡稱CDC),SQLServer為實時更新數據同步提供了CDC機制,類似于Mysql的binlog,將數據更新操作維護到一張CDC表中。開啟CDC的源表在插入INSERT、更新UPDATE和刪除DELETE活動時會插入數據到日志表中。cdc通過捕獲進程將變更數據捕獲到變更表中,通過cdc提供的查詢函數,可以捕獲這部分數據。詳情可以查看官方介紹:關于變更數據捕獲 (SQL Server)
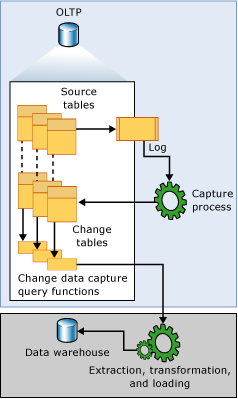
優點:提供易于使用的API 來設置CDC 環境,縮短ETL 的時間,無需修改業務系統表結構。
缺點:受數據庫版本的限制,實現過程相對復雜。
CDC增量抽取
先決條件
1. 已搭建好Kafka集群,Zookeeper集群;
2. 源數據庫支持CDC,版本采用開發版或企業版。
案例環境:
Ubuntu 20.04
Kafka2.13-2.7.0
Zookeeper 3.6.2
SQL Server 2012
步驟
除了數據庫開啟CDC支持以外,主要還是要將變更的數據通過Kafka Connect傳輸數據,Debezium是目前官方推薦的連接器,它支持絕大多數主流數據庫:MySQL、PostgreSQL、SQL Server、Oracle等等,詳情查看Connectors。
1. 數據庫步驟
開啟數據庫CDC支持
在源數據庫執行以下命令:
EXEC sys.sp_cdc_enable_db GO
附上關閉語句:
exec sys.sp_cdc_disable_db
查詢是否啟用
select * from sys.databases where is_cdc_enabled = 1
相關推薦
相關下載
熱門閱覽
- 1SQL開發知識:MyBatis SQL xml處理小于號與大于號正確的格式
- 2SQL基礎:SQL?Server的全文搜索功能
- 3SQL開發知識:SQL中Truncate的用法
- 4數據庫恢復之 delete誤刪數據使用SCN號恢復的詳細方希
- 5SQL開發知識:SQL Server數據庫查找表名或列名中包含空格的表和列
- 6SQL異常:教你sqlserver連接錯誤之SQL評估期已過的問題解決方法
- 7SQL開發知識:SQL Server執行動態SQL的正確方法
- 8數據安全:SQL Server2019數據庫備份與還原腳本(批量備份)
- 9SQL基礎:SQLServer2019 數據庫的基本使用之圖形化界面操作的實現
- 10SQL開發知識:關于SQL Server數據庫觸發器詳解
- 11SQL開發知識:SQL Server Management Studio(SSMS)復制數據庫的方法
- 12SQL開發知識:SQL Server非動態 SQL語句來對動態查詢進行執行
最新排行
- 1SQL開發知識:SQL注入工具
- 2SQL開發知識:SQL 在自增列插入指定數據的操作方法
- 3Sql Server2012數據庫使用IP登錄服務器的配置教程
- 4SQL開發知識:Navicat導出.sql文件方法
- 5SQL開發知識:SQL Server表和索引存儲結構
- 6SQL開發知識:Sql注入原理簡介
- 7SQL開發知識:SQL Server Management Studio(SSMS)復制數據庫的方法
- 8SQL開發知識:SQL Server執行動態SQL的正確方法
- 9SQL開發知識:SQL Server Parameter Sniffing及其改進方法
- 10SQL開發知識:sql server2008調試存儲過程的步驟
- 11SQL開發知識:SQL Server非動態 SQL語句來對動態查詢進行執行
- 12一文帶你詳解SQL Server 2016數據庫快照代理過程

網友評論